
Uruchamianie zaawansowanego wyszukiwania RAG za pomocą Neo4j
Obecnie aplikacje wykorzystujące technologię generowania rozszerzonego wyszukiwania (RAG) można wdrożyć w ciągu zaledwie kilku minut. Większość aplikacji RAG, takich jak przeszukiwanie i streszczanie PDF czy innego dokumentu tekstowego wykorzystuje podstawowe wyszukiwanie podobieństw wektorowych w celu pobrania odpowiednich informacji z bazy danych i przekazania ich do LLM w celu wygenerowania ostatecznej odpowiedzi.
Jednak podstawowe wyszukiwanie wektorów nie jest wystarczająco niezawodne, aby obsłużyć wszystkie przypadki użycia. Proces wyszukiwania podobieństwa wektorów porównuje jedynie treść semantyczną elementów na podstawie wspólnych słów i pojęć, bez względu na inne aspekty danych. Aplikacja RAG oparta na podstawowym wyszukiwaniu wektorowym nie będzie integrować kontekstu ze strukturą danych w celu zaawansowanego rozumowania.
W tym poście na blogu zobaczysz inną metodę tworzenia aplikacji RAG, która korzysta z kontekstu danych, aby odpowiedzieć na bardziej złożone pytania i wziąć pod uwagę szerszy kontekst.
Dokumenty nadrzędne i podrzędne
Termin "dokument" odnosi się zazwyczaj do tekstowych lub multimedialnych treści, które są analizowane, indeksowane i przetwarzane przez modele językowe w celu wydobycia znaczenia, informacji lub cech charakterystycznych. Kiedy mówimy o "dokumencie" w kontekście wektorowego wyszukiwania, mamy na myśli reprezentację takiego zasobu, który może być analizowany i manipulowany przez algorytmy "sztucznej inteligencji" w celu przetwarzania, analizy lub ekstrakcji informacji.
Przy indeksowaniu dokumentów trzeba zmierzyć się z co najmniej dwoma problemami. Pierwszy to ograniczenia modeli które tworzą wektory dokumentu ("embeddings") - treść może mieć ograniczoną długość. Drugi problem to znajdywanie podobieństw - wyszukiwanie wektorowe działa niezbyt dobrze jeśli mamy krótką sentencję i szukamy podobieństwa w długiej (istnieją specjalnie do tego celu zaprojektowane modele ale nawet one nie robią tego znakomicie).
Zatem bezpośrednie użycie wektora źródłowego dokumentu jest nieefektywne. Duże dokumenty można podzielić na mniejsze fragmenty, dla których obliczane są wektory, co poprawia indeksowanie w przypadku wyszukiwania podobieństw. Chociaż te wektory krótszej informacji lepiej sprawdzają się w znajdywaniu podobieństw (zwykle zapytanie jest krótkie), pobierany jest oryginalny duży dokument, ponieważ zapewnia lepszy kontekst dla odpowiedzi. W tej koncepcji mamy pełny dokument i powiązane z nim krótkie dokumenty w formie pytań związanych kontekstowo z tym dokumentem.
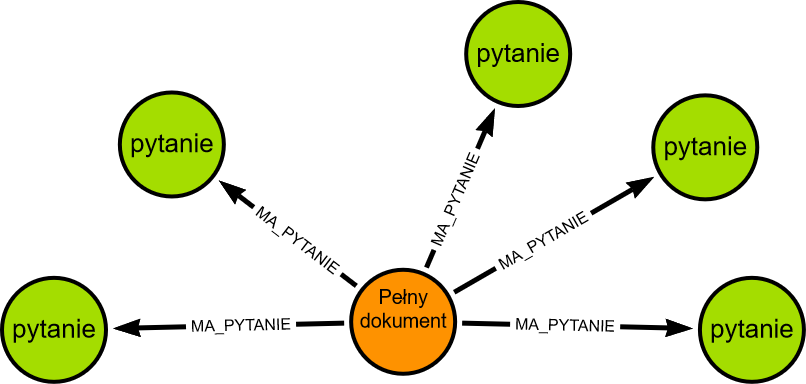
LLM może być użyty do wygenerowania tych pytań, na które odpowiada dokument.
Nie indeksujemy samego dokumentu ale pytania, co zapewnia większe podobieństwo do pytań użytkowników. Dostarczenie właściwego dokumentu do modelu odbywa się poprzez znalezienia powiązanego z dokumentem pytania i pobrania pełneg dokumentu nadrzędnego w celu zapewnienia pełnego kontekstu, stąd nazwa „wyszukiwarka dokumentów nadrzędnych”.
Przykład połączenia modelu językowego i Neo4j
Powyżej została opisana koncepcja rozbicia obszernej informacji na mniejsze fragmenty które zostały zindeksowane. Poniższy przykład demonstruje jak można wykorzystać informacje biznesowe przechowywane w grafowej bazie danych. Nasze testowe dane to informacje o kliencie i powiązane z klientem reklamacje.
Dane testowe
Gotowe polecenie poniżej utworzy dwóch klientów, produkty, i węzły otwartych przez tych klientów reklamacji.
(CustomerX:Customer {name: 'Honeywell International, Inc.', customer_id: 111, status: 'new', customer_value: 'high-value', industry: 'Safety and health'}),
(CustomerY:Customer {name: 'Chevron Corp. (CVX)', customer_id: 222, status: 'existing', customer_value: 'low-value', industry: 'Oil and gas production and oil refining'}),
(Complaint1:Complaint {complaint_id: 10, date: '2024-05-10', reason: 'Damaged packaging', status: 'Closed', solution: 'New packaging was delivered to the customer along with a free product'}),
(Complaint2:Complaint {complaint_id: 20, date: '2024-05-12', reason: 'Item expired', status: 'Open', solution: 'not provided yet'}),
(Complaint3:Complaint {complaint_id: 30, date: '2024-05-02', reason: 'Goods not as described', status: 'In Progress', solution: 'not provided yet'}),
(CustomerX)-[:HAS_COMPLAINT]->(Complaint1),
(CustomerX)-[:HAS_COMPLAINT]->(Complaint2),
(CustomerX)-[:HAS_COMPLAINT]->(Complaint3),
(ProductA:Product {name: 'Product A', product_id: 1000, category: 'seafood'}),
(ProductB:Product {name: 'Product B', product_id: 1001, category: 'beverage'}),
(ProductC:Product {name: 'Product C', product_id: 1002, category: 'bakery'}),
(ProductD:Product {name: 'Product D', product_id: 1003, category: 'seafood'}),
(ProductE:Product {name: 'Product E', product_id: 1004, category: 'meat'}),
(ProductF:Product {name: 'Product F', product_id: 1005, category: 'deli'}),
(Complaint1)-[:APPLIES_TO_PRODUCT]->(ProductA),
(Complaint1)-[:APPLIES_TO_PRODUCT]->(ProductB),
(Complaint2)-[:APPLIES_TO_PRODUCT]->(ProductC),
(Complaint2)-[:APPLIES_TO_PRODUCT]->(ProductD),
(Complaint2)-[:APPLIES_TO_PRODUCT]->(ProductE),
(Complaint3)-[:APPLIES_TO_PRODUCT]->(ProductF),
(Complaint3)-[:APPLIES_TO_PRODUCT]->(ProductE),
(Complaint4:Complaint {complaint_id: 40, date: '2024-05-30', reason: 'Delivery not in time', status: 'closed', solution: 'not provided yet'}),
(Complaint5:Complaint {complaint_id: 50, date: '2024-05-25', reason: 'Wrong delivery address', status: 'closed', solution: 'not provided yet'}),
(CustomerY)-[:HAS_COMPLAINT]->(Complaint4),
(CustomerY)-[:HAS_COMPLAINT]->(Complaint5)
Po imporcie danych otrzymamy graf:

Kod programu
W poniższyszym przykładzie używamy Neo4j w dwóch celach; przechowywujemy tam informacje oraz używamy Neo4 do wyszukiwania wektorowego. Nasz model językowy to 'mistral' w środowisku Ollama. Komponentem który łączy te środowiska jest Langchain.
Baza wektorów - Neo4j
Oprogramowaniem w którym przechowujemy dane oraz wektory ("embeddings") to grafowa baza danych - Neo4j. Rozpoczynamy od połączenia z Neo4j - mamy już tam graf który wgraliśmy wcześniej. Komponent 'Neo4jVector' i metoda 'from_existing_graph' pełni dwie role: 1. Inicjuje instancję Neo4jVector przy użyciu podanych parametrów i istniejącego wykresu. 2. Weryfikuje istnienie indeksów i tworzy nowe, jeśli nie istnieją.
Wektory obliczone, koordynaty w Neo4j gdzie umieściliśmy dane, zostały obliczone przy pomocy modelu 'mistral': embeddings = OllamaEmbeddings(model="mistral"). Parametr 'text_node_properties=['name', 'industry']' mówi że wykorzystaliśmy properties 'name' i 'industry' węzłów.
embeddings = OllamaEmbeddings(model="mistral")
retrieval_query = """
OPTIONAL MATCH (node)-[:HAS_COMPLAINT]->(p)
WITH node, score, collect(p.reason) AS reasons, collect(p.status) AS status
RETURN node.name+' industry: '+node.industry+', compliant reasons reported by company: '+reduce(s = '', reason in reasons | s + reason + ',') AS text,
score,
node {.*, embedding: Null, compliant_reasons: reasons} AS metadata
"""
complaints_vector = Neo4jVector.from_existing_graph(
embeddings,
url=url,
username=username,
password=password,
index_name='complaints',
node_label="Customer",
text_node_properties=['name', 'industry'],
embedding_node_property='embedding',
retrieval_query=retrieval_query,
)
Sprawdzenie wyszukiwania podobnych wektorów
Sprawdźmy czy wyszukiwanie podobnych fraz działa - dla frazy naszego tekstu dla którego szukamy podobieństw tworzymy wektory i poszukujemy wektorów o podobnych wartościach w bazie danych. Robimy to poleceniem 'complaints_vector.similarity_search()'. Wektor frazy 'What complaints reasons opened by the Honeywell International' jest utworzony tym samym modelem który został użyty do umieszczenia danych w bazie. Użyliśmy tam parametru 'k=1' co oznacza że zapytanie ma zwrócić tylko jeden, najbardziej pasujący dokument.
Są to tak zwane 'kwargs'. W modelach LLM (Large Language Models), takich jak Ollama, GPT, kwargs jest skrótem od "keyword arguments" (argumenty słownikowe). Jest to konwencja nazewnictwa w Pythonie, która oznacza argumenty funkcji, które są przekazywane w postaci słownika.
result1 = complaints_vector.similarity_search("What complaints reasons opened by the Honeywell International", k=1)
print('------------------------------ Similar docs:\n')
print(result1)
Budujemy retrieval
plot_retriever = RetrievalQA.from_llm(
llm=llm,
#retriever=complaints_vector.as_retriever(search_kwargs={"k": 1}),
retriever=complaints_vector.as_retriever(),
return_source_documents=True
)
Tutaj także mamy możliwość decydowania jakiej ilości dokumentów uzyskanych z 'retrievera' użyjemy do generowania odpowiedzi przez LLM; search_kwargs={"k": 1}. Teoretycznie im więcej dokumentów jako źródło prześlemy do modelu, tym dokładniejsza będzie odpowiedź. W praktyce oznacza to jednak duży koszt otrzymania odpowiedzi; czas oczekiwania.
Parametr 'return_source_documents=True' mówi że chcemy by retreival zwrócił informację jakich dokumentów użył do wygenerowania odpowiedzi.
Retrieval query
Parametr 'retrieval_query=retrieval_query' metody 'Neo4jVector.from_existing_graph' korzysta z zapytania [zobacz przeszukiwanie indeksów wektorów w Neo4j] i jego kod źródłowy ma postać:
read_query = (
"CALL db.index.vector.queryNodes($index, $k, $embedding) "
"YIELD node, score "
) + retrieval_query
Jak widzisz, 'retrieval_query' jest opcjonalnym parametrem. Z kodu możemy zauważyć, że wyszukiwanie podobieństwa wektorów jest zakodowane na stałe. Mamy jednak wtedy możliwość dodania wszelkich kroków pośrednich i zwrócenia dodatkowych informacji ('+ retrieval_query'). Zapytanie pobierające musi zwrócić następujące trzy kolumny:
- text (String): Zwykle są to dane tekstowe powiązane z pobranym węzłem. Może to być główna treść węzła, nazwa, opis lub inna informacja tekstowa.
- score (Float): reprezentuje wynik podobieństwa między wektorem zapytania a wektorem powiązanym ze zwróconym węzłem. Wynik określa ilościowo stopień podobieństwa zapytania do zwróconych węzłów, często w skali od 0 do 1
- metadata (Disctionary): Jest to bardziej elastyczna kolumna, która może zawierać dodatkowe informacje o węźle lub wyszukiwaniu. Może to być słownik (lub mapa) zawierający różne atrybuty lub właściwości, które zapewniają większy kontekst zwróconemu węzłowi.
W naszym przykładzie opcjonalne zapytanie ma postać:
retrieval_query = """
OPTIONAL MATCH (node)-[:HAS_COMPLAINT]->(p)
WITH node, score, collect(p.reason) AS reasons, collect(p.status) AS status
RETURN node.name+' industry: '+node.industry+', compliant reasons reported by company: '+reduce(s = '', reason in reasons | s + reason + ',') AS text,
score,
node {.*, embedding: Null, compliant_reasons: reasons} AS metadata
"""
Dołączamy węzły 'Complaint', oznaczone "p", i z nich pobieramy wartości z properties 'reason' z których poleceniem 'reduce' robimy agregację informacji z węzłów do postaci pojedynczej wartości (stringu). By model 'zorientował się' że to są właśnie powody reklamacji dodajemy string 'compliant reasons reported by company:'
Metadata
Kolumna 'metadata' daje nam ogromna swobodę prezentowania wyników dostarczonych przez LLM; możesz np. przy odpowiedzi z modelu dołączyć linki do źródłowych dokumentów, informację rozszerzającą. Nasz kod:
node {.*, embedding: Null, compliant_reasons: reasons} AS metadata
Dał nam rezultat w postaci wylistowania wartości wszystkich properties węzła (.*) a 'complaint_reasons: reasons' zawiera powody reklamacji. Oto rezultat wykonania:
metadata={'status': 'new', 'name': 'Honeywell International, Inc.', 'customer_value': 'high-value', 'compliant_reasons': ['Goods not as
described', 'Item expired', 'Damaged packaging']
Kod programu
Finalny kod programu:
from langchain_community.graphs import Neo4jGraph
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores.neo4j_vector import Neo4jVector
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
url = "bolt://localhost:7687"
username ="neo4j"
password = "xxx"
graph = Neo4jGraph(
url=url,
username=username,
password=password
)
embeddings = OllamaEmbeddings(model="mistral")
retrieval_query = """
OPTIONAL MATCH (node)-[:HAS_COMPLAINT]->(p)
WITH node, score, collect(p.reason) AS reasons, collect(p.status) AS status
RETURN node.name+' industry: '+node.industry+', compliant reasons reported by company: '+reduce(s = '', reason in reasons | s + reason + ',') AS text,
score,
node {.*, embedding: Null, compliant_reasons: reasons} AS metadata
"""
complaints_vector = Neo4jVector.from_existing_graph(
embeddings,
url=url,
username=username,
password=password,
index_name='complaints',
node_label="Customer",
text_node_properties=['name', 'industry'],
embedding_node_property='embedding',
retrieval_query=retrieval_query,
)
result1 = complaints_vector.similarity_search("What complaints reasons opened by the Honeywell International", k=1)
print('------------------------------ Similar docs:\n')
print(result1)
print('\n------------------------------ Source documents used in llm:\n')
llm = Ollama(base_url='http://localhost:11434', model="mistral", temperature=0)
plot_retriever = RetrievalQA.from_llm(
llm=llm,
#retriever=complaints_vector.as_retriever(search_kwargs={"k": 1}),
retriever=complaints_vector.as_retriever(),
return_source_documents=True
)
question = "What are complaint reasons reported by Honeywell International ?"
response = plot_retriever.invoke(question)
print(response)
print('\n------------------------------ Complaint reasons:\n')
result = response["result"]
print(result)
Rezultat
Oto rezultat wykonania powyższego kodu; podobne dokumenty, jakie dokumenty zostały przesłane do LLM, informacja wygenerowana przez LLM:
------------------------------ Similar docs:
[Document(page_content='Honeywell International, Inc. industry: Safety and health, compliant reasons reported by company: Goods not as described,Item expired,Damaged packaging,', metadata={'status': 'new', 'name': 'Honeywell International, Inc.', 'customer_value': 'high-value', 'compliant_reasons': ['Goods not as described', 'Item expired', 'Damaged packaging'], 'industry': 'Safety and health', 'customer_id': 111}), Document(page_content='Chevron Corp. (CVX) industry: Oil and gas production and oil refining, compliant reasons reported by company: Wrong delivery address,Delivery not in time,', metadata={'status': 'existing', 'name': 'Chevron Corp. (CVX)', 'customer_value': 'low-value', 'compliant_reasons': ['Wrong delivery address', 'Delivery not in time'], 'industry': 'Oil and gas production and oil refining', 'customer_id': 222})]
------------------------------ Source documents used in llm:
{'query': 'What are complaint reasons reported by Honeywell International ?', 'result': ' The complaint reasons reported by Honeywell International, according to the context provided, include "Goods not as described," "Item expired," and "Damaged packaging."', 'source_documents': [Document(page_content='Chevron Corp. (CVX) industry: Oil and gas production and oil refining, compliant reasons reported by company: Wrong delivery address,Delivery not in time,', metadata={'status': 'existing', 'name': 'Chevron Corp. (CVX)', 'customer_value': 'low-value', 'compliant_reasons': ['Wrong delivery address', 'Delivery not in time'], 'industry': 'Oil and gas production and oil refining', 'customer_id': 222}), Document(page_content='Honeywell International, Inc. industry: Safety and health, compliant reasons reported by company: Goods not as described,Item expired,Damaged packaging,', metadata={'status': 'new', 'name': 'Honeywell International, Inc.', 'customer_value': 'high-value', 'compliant_reasons': ['Goods not as
described', 'Item expired', 'Damaged packaging'], 'industry': 'Safety and health', 'customer_id': 111})]}
------------------------------ Complaint reasons:
The complaint reasons reported by Honeywell International, according to the context provided, include "Goods not as described," "Item expired," and "Damaged packaging."
Format odpowiedzi
'Result', response = plot_retriever.invoke(question), ma format 'dictionary'. Słowniki służą do przechowywania wartości danych w parach klucz : wartość. Słownik to zbiór uporządkowany*, podlegający zmianom i nie pozwalający na duplikowanie.