Apache Flink - przetwarzanie danych
Domyślnym sposobem tworzenia aplikacji Apache Flink jest użycie Flink SQL. Ułatwia on tworzenie aplikacji przetwarzania strumieniowego przy użyciu standardowego SQL. Łatwo jest nauczyć się Flink, jeśli kiedykolwiek pracowałeś z bazą danych lub systemem podobnym do SQL, zgodnym z ANSI-SQL 2011.
Podobnie jak w przypadku wszystkich silników SQL, zapytania Flink działają na szczycie tabel. Różnią się one jednak od tradycyjnej bazy danych, ponieważ Flink nie zarządza danymi składowanymi w statycznych tabelach; zamiast tego jego zapytania działają w sposób ciągły na danych zewnętrznych (z tabel baz danych lub plików powstają tabele dynamiczne w programie Flink a po przetworzeniu danych mogą być z powrotem zapisane do tradycyjnych tabel baz danych i do plików).
Potoki przetwarzania danych Flink zaczynają się od danych źródłowych. Dane źródłowe tworzą wiersze obsługiwane podczas wykonywania zapytania; są to dynamiczne tabele Flink, do których odwołuje się klauzula FROM zapytania. Mogą to być topiki Kafki, bazy danych, systemy plików lub dowolny inny system z którego Flink wie jak korzystać.
Zanim zaczniesz czytać dalej, upewnij się że przeczytałe(a)ś wcześniejsze artykuły jak zainstalować Apache Flink [uruchomienie-apache-flink-w-windows] i jak utworzyć pierwszą aplikację w tym środowisku [pierwsza-transformacja-w-apache-flink]
Raz jeszcze: tabele dynamiczne Flink nie są tabelami baz danych - powstają one poprzez odczytanie tabel baz danych [np MySQL, Oracle], plików [np. CSV] lub pochodzą z innych źródeł [np. Kafka]. Flink używa swoich własnych tabel - przeczytaj o nich więcej na stronie Apache Flink
Treść tego artykułu
Poniżej znajdziesz opis podstaw korzystania z Flink SQL API - niezbędne informacje by tworzyć programy w Apache Flink. Dowiesz się jak:
- Połączyć się z bazą danych
- Odczytać tabelę bazy danych
- Przetworzyć dane
- Zapisać dane do bazy danych
Połączenie Flink z bazą danych
Utwórz nowy projekt Maven lub Java w Eclipse [zobacz wcześniejszy artykuł jak stworzyć projekt w Flink w Eclipse]. Flink potrzebuje zależności MAVEN by korzystać z protokołu JDBC. Jeśli Twoim projektem jest projekt Java, przekształć go w projekt Maven. Prawym przyciskiem kliknij na nazwie projektu i z menu wybierz "Configure => Convert to Maven Project"

Wartości w oknie "Create new POM" pozostaw puste i kliknij na "Finish". W efekcie tego w katalogu projektu pojawi sie plik "pom.xml". Plik ten ma postać:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>flink-jdbc</groupId>
<artifactId>flink-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<release>11</release>
</configuration>
</plugin>
</plugins>
</build>
</project>
W tym pliku musisz dodać zależność Maven, "flink-connector-jdbc" [wg. instrukcji dokumentacji Flink] wklejając poniższy fragment w strukturę pliku "pom.xml"
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.14.5</version>
</dependency>Przed tagiem zamykajacym </project> umieść tag <dependencies> i zamknij go </dependencies>. Wystarczy ze rozpoczniesz pisać "<de" a Eclipse podpowie Ci składnię. Twój "pom.xml" powinien teraz wyglądać tak:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>flink-jdbc</groupId>
<artifactId>flink-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<release>11</release>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.14.5</version>
</dependency>
</dependencies>
</project>
Następnie zaktualizuj projekt klikając prawym przyciskiem myszy na projekt i wybierając "Maven => Update project" [w oknie które się pojawi powinien być domyślnie wybrany Twoj projekt - kliknij "OK"].
Dodaj sterownik JDBC
Instalacja Flink nie posiada domyślnie sterowników JDBC do baz danych. Musisz je pobrać ze stron producentów baz danych. Wejdź na stronę Flink i pobierz odpowiedni plik a następnie umieść go w katalogu "lib". Dla bazy MySQL konektorem JDBC jest plik "mysql-connector-java-8.0.30.jar" ze strony https://repo.maven.apache.org/maven2/mysql/mysql-connector-java/8.0.30/.
Następnie dodaj plik sterownika do "classpath" projektu. Prawym przyciskiem myszy kliknij na katalog "src": "Build path => Configure build path". Kliknij na "Classpath" w zakładce "Libraries", kliknij na "Add Externaj JARs..." i dodaj właśnie pobrany plik. Kliknij "Apply and close". Gotowe.
Odczytujemy tabele z bazy danych MySQL
Nasza testowa tabela "clients" znajduje sie w bazie danych o nazwie "test" i ma strukturę:
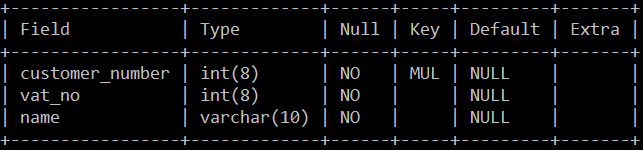
Oto kod klasy programu który łączy się z bazą MySQL, pobiera dane z tabeli i tworzy tabelę dynamiczną Flink a następnie wyświetla w konsoli zawartość tej tabeli:
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
public class FlinkJDBC {
public static void main(String[] args) throws Exception {
//Definiuje wszystkie parametry, które inicjują środowisko tabeli.
//Te parametry są używane tylko podczas tworzenia inicjalizacji TableEnvironment i nie można ich później zmienić.
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inBatchMode()
.build();
final TableEnvironment tEnv = TableEnvironment.create(settings);
//Laczymy sie z MySQL i pobieramy dane z tabeli 'clients' do tabeli Flink 'MyClients'
tEnv.executeSql("CREATE TABLE MyClients ("
+ " customer_number INT, "
+ " vat_no INT, "
+ " name STRING, "
+ " PRIMARY KEY (customer_number) NOT ENFORCED"
+ " ) WITH ( "
+ " 'connector' = 'jdbc', "
+ " 'url' = 'jdbc:mysql://localhost:3306/test', "
+ " 'username' = 'user_name', "
+ " 'table-name' = 'clients', "
+ " 'password' = ''"
+ ")");
//Testowy select
tEnv.sqlQuery("SELECT * FROM MyClients")
.execute()
.print();
}
}
Rezultat który ujrzymy w konsoli Eclipse IDE po kliknięciu na "Run => Run":
+-----------------+-------------+--------------------------------+
| customer_number | vat_no | name |
+-----------------+-------------+--------------------------------+
| 1 | 11 | client1 |
| 2 | 22 | client2 |
+-----------------+-------------+--------------------------------+
2 rows in set
Przetwarzamy dane
Petla przez wszystkie rekordy tabeli:
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.types.Row;
public class FlinkJDBC {
public static void main(String[] args) throws Exception {
//Definiuje wszystkie parametry, które inicjują środowisko tabeli.
//Te parametry są używane tylko podczas tworzenia inicjalizacji TableEnvironment i nie można ich później zmienić.
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inBatchMode()
.build();
final TableEnvironment tEnv = TableEnvironment.create(settings);
//Laczymy sie z MySQL i pobieramy dane z tabeli 'clients' do tabeli Flink 'MyClients'
tEnv.executeSql("CREATE TABLE MyClients ("
+ " customer_number INT, "
+ " vat_no INT, "
+ " name STRING, "
+ " PRIMARY KEY (customer_number) NOT ENFORCED"
+ " ) WITH ( "
+ " 'connector' = 'jdbc', "
+ " 'url' = 'jdbc:mysql://localhost:3306/test', "
+ " 'username' = 'root', "
+ " 'table-name' = 'clients', "
+ " 'password' = ''"
+ ")");
//Petla przez rekordy tabeli
TableResult tableResult1 = tEnv.executeSql("SELECT * FROM MyClients");
try (org.apache.flink.util.CloseableIterator<Row> it = tableResult1.collect()) {
while(it.hasNext()) {
Row row = it.next();
//Przetwarzanie rekordu (tutaj prosty print do konsoli):
String rekord = row.getField("name").toString();
System.out.println(rekord);
}
}
}
}
Zapisanie danych do tabeli MySQL
Zapisać dane do tabeli utworzonej z połączena JDBC możemy na dwa sposoby. Pierwszy, naturalny, to pobranie rekordów z innej tabeli dynamicznej Flink. Wykonujemy select i wklejamy rezultat do tabeli JDBC:
tEnv.executeSql("INSERT INTO MyClients SELECT customer_number, vat_no, name FROM csv_table");
W powyższym przykładzie "cs_table" jest linkiem do pliku CSV. Pamiętaj że we Flink tabele są zawsze linkiem do danych z jakiegoś źródła. Nie można utworzyć we Flink pustej tabeli. Obejściem tych ograniczeń może być użycie Table Store [więcej tutaj] lub Hive Dialect [więcej tutaj].
Drugim sposobem jest wklejenie wartości komendą SQL. Np. przetwarzasz dane i chcesz utworzyć zupełnie nowy rekord w tabeli:
tEnv.executeSql("INSERT INTO MyClients (customer_number, vat_no, name) VALUES (1000, 23, 'client3')");
Czytając wszystkie trzy artykuły [uruchomienie Flink, pierwsza transformacja w Apache Flink, Flink - przetwarzanie danych] szybko zdobędziesz podstawową wiedzę jak korzystać z tego środowiska.