Optyczne rozpoznawanie znaków (OCR) w Pentaho
Koncept
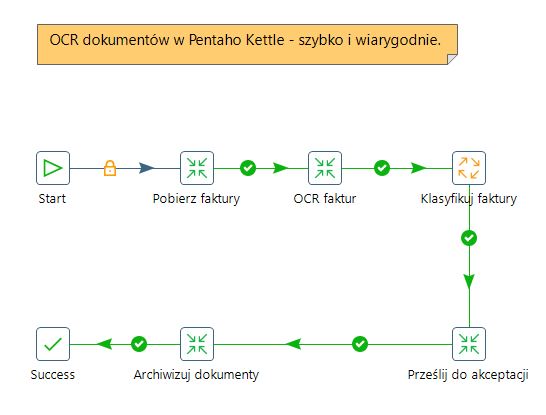
Pentaho PDI jest idealnym narzędziem do przetwarzania plików, formatowania danych, ekstrakcji informacji, separowania danych w zależności od ich przeznaczenia. Idealne narzędzie by użyć go do zarządzania dokumentami - np. stworzyć system do obiegu faktur. Jednak jednej rzeczy Pentaho nie ma - optycznego rozpoznawania znaków. A dokumenty często są w formie obrazów. Musimy dokonać OCR'owania by odczytać daty, nazwy, numery. Czy istnieje jakiś sposób by sobie z tym poradzić? Tak, istnieje.
Dlaczego moi klienci odchodzą?
Istnieje wiele powodów dlaczego klineci moga rezygnować z zakupu usługi lub produktów które sprzedaje Twoja firma. W artykule retencja klientów opisywaliśmy czym jest retencja, jak odczytywać sygnały o potencjalnym odejściu klienta i jak gromadzić wiedzę na ten temat. Każdy z potencjalnych, najczęściej występujących sygnałów jest miarodajny, ale rozpatrywany samodzielnie nie jest wystarczająco wyraźny by wyróżnić grupę klientów zagrożonych odejsciem i zareagować odpowiednio wcześniej nie dopuszczając do utraty klienta.
Zatem zdefiniowałęś kilka atrybutów których monitorowanie uznałeś za ważne i miarodajne i teraz chciałbyś wyciągnąć wnioski z ich analizy. Powiedzmy że podzieliłeś klientów na dwie klasy; tych których utraciłeś i tych którzy ciągle są klientami Twojej firmy. Masz też informację na temat częstotliwości zakupów klientów, ich wysokości, ilości kupowanych przez nich kategorii produktów.
Czy klienci którzy odchodzą wykazują inne zachowania niż aktywni klienci? Czy tworzą inną grupę niż ci którzy nadal kupują? Czy na tej podstawie stworzę model który mogę zastosować do wykrywania klienta zagrożonego utratą?
Według badania 3M przetwarzanie informacji zawartej w grafice jest aż 60 tysięcy razy szybsze niż przetwarzanie tekstu. Dlaczego by zatem prezentować wyniki podziału klientów na klastry wg powyższych założeń w postaci tekstu? Przezentacja ich w postaci wykresu pozwoli Ci te informację otrzymać w krótkiej chwili - w sekundy zorientujesz się co łączy klientów danej klasy i jakie są różnice miedzy tymi klasami (aktywni - utraceni).
Magiczne sztuczki – grafowe bazy danych
Grafowe bazy danych nowym „hype” genialnego IT marketingu?
Praktycznie każda aplikacja której używamy wykorzystuje bazę danych. Wszyscy, a przynajmniej tak być powinno, słyszeliśmy o relacyjnych bazach danych i najczęściej obsługujących je uniwersalnym języku SQL. "Bazy relacyjne" gdyż dane są przechowywane w uporządkowanych ciągach wartości (inaczej „krotek”). Opisane tworzą rekordy i tabele z występującymi między nimi relacjami. Relacyjne bazy danych istnieją na rynku od lat 80tych i są bezwzględnie najczęściej używanym typem baz danych.
Jednak w latach dwutysięcznych pojawiły się nowe typy baz danych NoSQL z których z kolei wyrosły grafowe bazy danych (nie „graficzne” jak to często błędnie jest tłumaczone).
Większość baz danych NoSQL przechowuje zestawy luźnych agregatów (w postaci dokumentów lub par klucz-wartość) – brak relacji między danymi, co ma pozytywny wpływ na prędkość ich działania. Utrudnia to jednak łączenie danych. Jedną ze strategii dodawania relacji do takich danych jest osadzenie identyfikatora jednego dokumenty wewnątrz innego dokumentu. Wymaga to jednak połączenia agregatów/danych na poziomie aplikacji (skomplikowana obsługa).
Grafowe bazy danych odróżnia od baz NoSQL to że przechowują relacje wraz z danymi. Ponieważ dane są fizycznie połączone w bazie danych, dostęp do tych relacji jest tak szybki jak dostęp do samych danych. Innymi słowy zamiast obliczać relację jak w relacyjnych bazach danych, grafowe bazy danych po prostu odczytują relacje z pamięci.
Produktem który zdominował rynek grafowych baz danych jest teraz Neo4j - zobacz jak łatwo zacząć korzystać z tej bazy [kurs który wprowadzi Cię w świat grafów]. Jeśli chcesz dowiedzieć się więcej o współczesnych możliwościach grafowych baz danych a, co ważniejsze, szukasz inspiracji co Ty możesz uzyskać dzięki nim - przeczytaj nasze przykłady użycia. Napisaliśmy tam co do czego możesz użyć grafowej bazy w swoim biznesie. W firmie która nie jest drugim Google, Facebookiemy czy Microsoftem.

Techniki „Data Mining”
Eksploracja danych nie jest nowym wynalazkiem, który pojawił się w erze cyfrowej. Ta koncepcja istnieje od ponad wieku, ale w latach 30. XX wieku stała się bardziej publiczna. Eksploracja danych to proces odkrywania wzorców w dużych zestawach danych obejmujących wykorzystywanie algorytmów (zwane często tajemniczo "uczeniem maszynowym"), statystyki i systemów baz danych. Pojęcie „eksploracja danych” jest mylące, ponieważ celem jest ekstrakcja wzorców i wiedzy z dużych ilości danych, a nie ekstrakcja samych informacji. Szukamy najczęściej wzorca nie gotowej informacji. Jest to również modne, pojemne hasło i jest często stosowane do dowolnej formy przetwarzania danych lub informacji.
Przejdźmy zatem przez spis najczęściej używanych technik stosowanych w eksploaracji danych („data mining”). Sam temat „data mining” jest na tyle pojemny że można by napisać o nim co najmniej kilka stron. Na nasze potrzeby przyjmijmy, że jest to po prostu praca z danymi. A w tej pracy stosujemy najczęściej techniki wymienione poniżej w akapicie „Techniki Data Mining”.